
《Apache Flink 必知必会》
一、走进Apache Flink
概念
- Flink是一个框架和分布式处理引擎,用来对无界和有界的数据流进行有状态的计算。
流引擎演进
- Apache Storm:纯流设计。延迟非常低,无法避免消息重复处理。
- Spark:以批为核心。解决了流计算语义正确性问题,但导致延迟比较高,10s级别延迟。
- Flink:第三代流引擎。低延迟、保证一致性语义、内置状态管理。
使用场景
- 事件驱动型应用
- 事件驱动表示一个事件会触发另一个或者是很多个后续的事件,然后这一系列事件会形成一些信息,基于这些信息需要做一定处理。
- 事件驱动型应用是一类具有状态的应用,会根据事件流中的事件触发计算、更新状态或进行外部系统操作。事件驱动型应用常见于实时计算业务中,比如:实时推荐,金融反欺诈,实时规则预警等。
- 数据分析型应用
- 如双 11 成交额实时汇总,包括PV、UV 的统计,环比、同比的比较,这些背后都涉及到大量信息实时的分析和聚合,这些都是 Flink 非常典型的使用场景。
- 数据管道型应用 (ETL)
- ETL(Extract-Transform-Load)是从数据源抽取/转换/加载/数据至目的端的过程。
- Flink 有非常丰富的 Connector,支持多种数据源和数据 Sink,囊括了所有主流的存储系统。另外它也有一些非常通用的内置聚合函数来完成 ETL 程序的编写,因此 ETL 类型的应用也是它非常适合的应用场景。
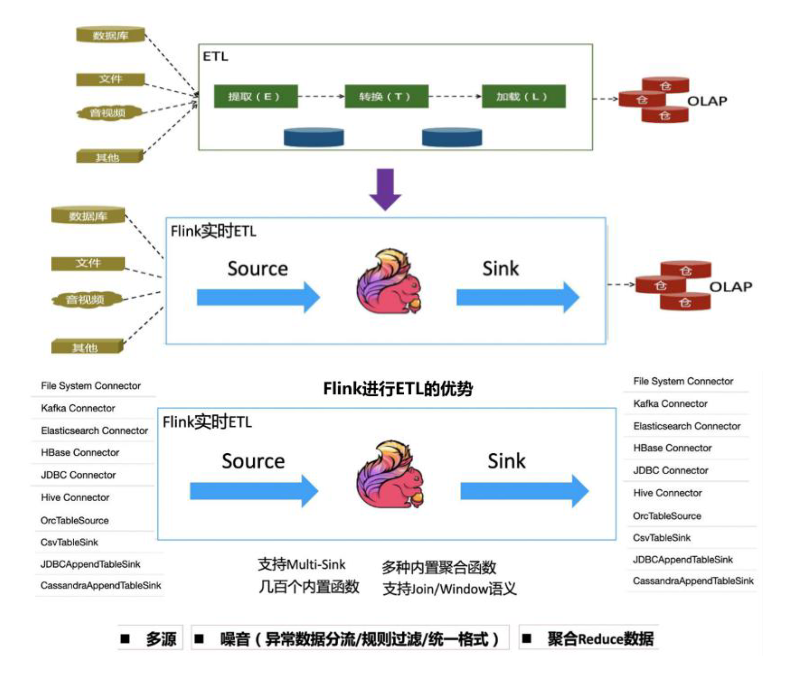
基本概念
(一) 核心概念
- Event Streams:即事件流,事件流可以是实时的也可以是历史的。Flink 是基于流的,但它不止能处理流,也能处理批,而流和批的输入都是事件流,差别在于实时与批量。
- State:Flink 擅长处理有状态的计算。通常的复杂业务逻辑都是有状态的,它不仅要处理单一的事件,而且需要记录一系列历史的信息,然后进行计算或者判断。
- (Event)Time:最主要处理的问题是数据乱序的时候,一致性如何保证。
- Snapshots:实现了数据的快照、故障的恢复,保证数据一致性和作业的升级迁移等。
(二)Flink 作业描述和逻辑拓扑
逻辑拓扑里面有 4 个称为算子或者是运算的单元,分别是 Source、Map 、KeyBy/Window/Apply 、Sink,我们把逻辑拓扑称为 Streaming Dataflow.
(三)Flink 物理拓扑
逻辑拓扑对应物理拓扑,它的每一个算子都可以并发进行处理,进行负载均衡与处理加速等。
二、Stream Processing with Apache Flin
DataStream API 概览及简单应用
- 逻辑层次
- 转换
- 分区
- 连接器
Flink 中的状态和时间
如果想要深入地了解 DataStream API,状态和时间是必须掌握的要点。 所有的计算都可以简单地分为无状态计算和有状态计算。无状态计算相对而言比 较容易。假设这里有个加法算子,每进来一组数据,都把它们全部加起来,然后把结 果输出去,有点纯函数的味道。纯函数指的是每一次计算结果只和输入数据有关,之
《剑指大数据——Flink学习精要(Java版)》
一、初识Flink
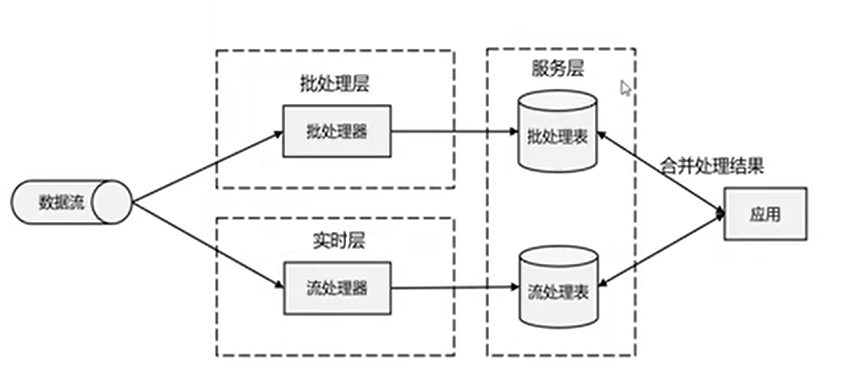
1. 框架演变
- lamda架构
- 使用双框架,流处理实时但不准确,批处理准确但延迟时间长。
- 使用流处理实时更新中间数据(低延迟),到某个时间点换成批处理的最终数据(准确率)。
- Flnik
- 高吞吐、低延迟、结果准确、状态一致性、能与众多常用存储系统连接、高可用、动态扩展
2. 分层API
- 越顶层越抽象(易用、语义),越低层越具体(能力丰富、灵活)
- 从高到低:SQL(最高层)、TABLE API(声明式领域)、DataStream/DataSet API(核心API)、有状态流处理(底层API)
二、Flink快速上手(maven)
1. pom依赖
<properties>
<flink.version>1.12.7</flink.version>
</properties>
<!-- artifactId里的2.12是scala版本 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-runtime-web_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
2. 批处理 & 3. 流处理
见demo
三、部署(略)
四、运行时架构
1. 系统架构
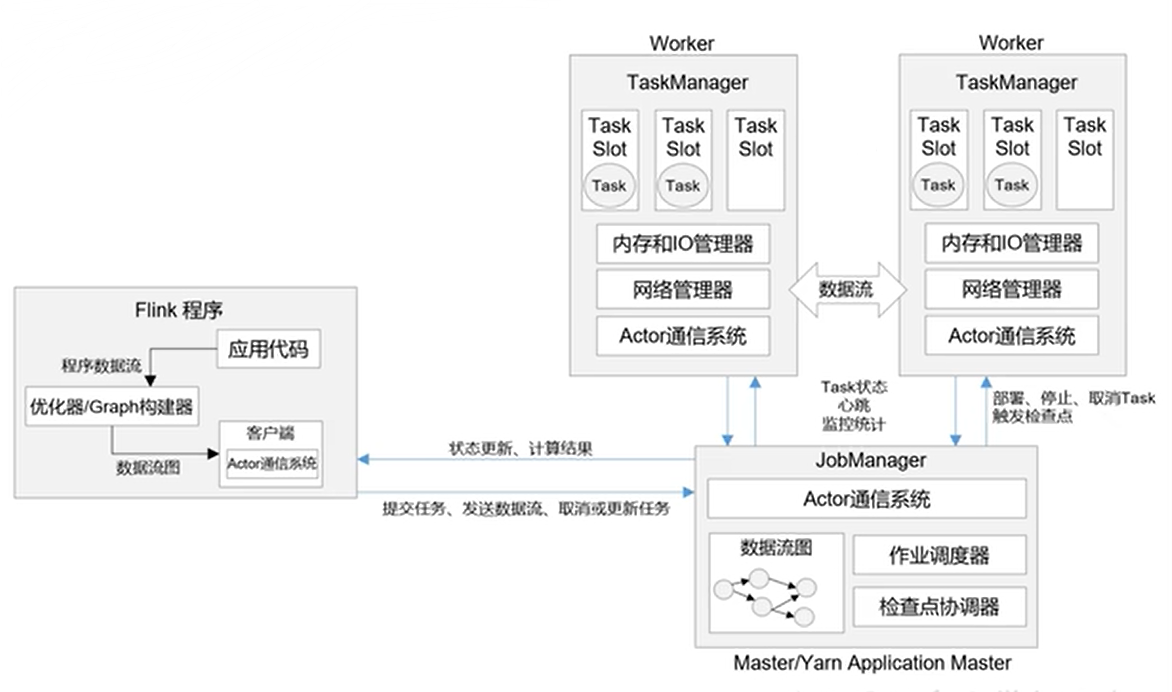
2. 作业管理器(JobManager)
- 控制一个应用程序执行的主进程,是Flink集群中任务管理和调度的核心。
- JobMaster(一般一个)
- JobMaster是JobManager中最核心的组件,负责处理单独的作业 (Job)。
- 在作业提交时,JobMaster会先接收到要执行的应用。一般是由客户端提交来的,包括: Jar包,数据流图(dataflow graph),和作业图(JobGraph)。
- JobMaster会把JobGraph转换成一个物理层面的数据流图,这个图被叫作”执行图”(ExecutionGraph),它包含了所有可以并发执行的任务。JobMaster会向资源管理器(ResourceManager)发出请求,申请执行任务必要的资源。一旦它获取到了足够的资源,就会将执行图分发到真正运行它们的TaskManager上。
- 在运行过程中,JobMaster会负责所有需要中央协调的操作,比如说检查点(checkpoints)的协调。
- 资源管理器(ResourceManager,一个)
- ResourceManager主要负责资源的分配和管理,在Flink集群中只有一个。所谓“资源””,主要是指TaskManager的任务槽(task slots)。任务槽就是Flink集群中的资源调配单元,包含了机器用来执行计算的一组CPU和内存资源。每一个任务(Task)都需要分配到一个slot上执行。
- 分发器(Dispatcher)
- Dispatcher主要负责提供一个REST接口,用来提交应用,并且负责为每一个新提交的作业启动一个新的JobMaster组件。Dispatcher也会启动一个Web UI,用来方便地展示和监控作业执行的信息。Dispatcher在架构中并不是必需的,在不同的部署模式下可能会被忽略掉。
- 任务管理器(TaskManager, 多个)
- Flink中的工作进程。通常在Flink中会有多个TaskManager运行,每个TaskManager都包含了一定数量的插槽(slots)。插槽的数量限制了TaskManager 能够并行处理的任务数量。
- 启动之后,TaskManager 会向资源管理器注册它的插槽;收到资源管理器的指令后,TaskManager 就会将一个或者多个插槽提供给JobMaster调用。JobMaster 就可以向插槽分配任务(tasks)来执行了。
- 在执行过程中,一个TaskManager 可以跟其它运行同一应用程序的TaskManager交换数据。
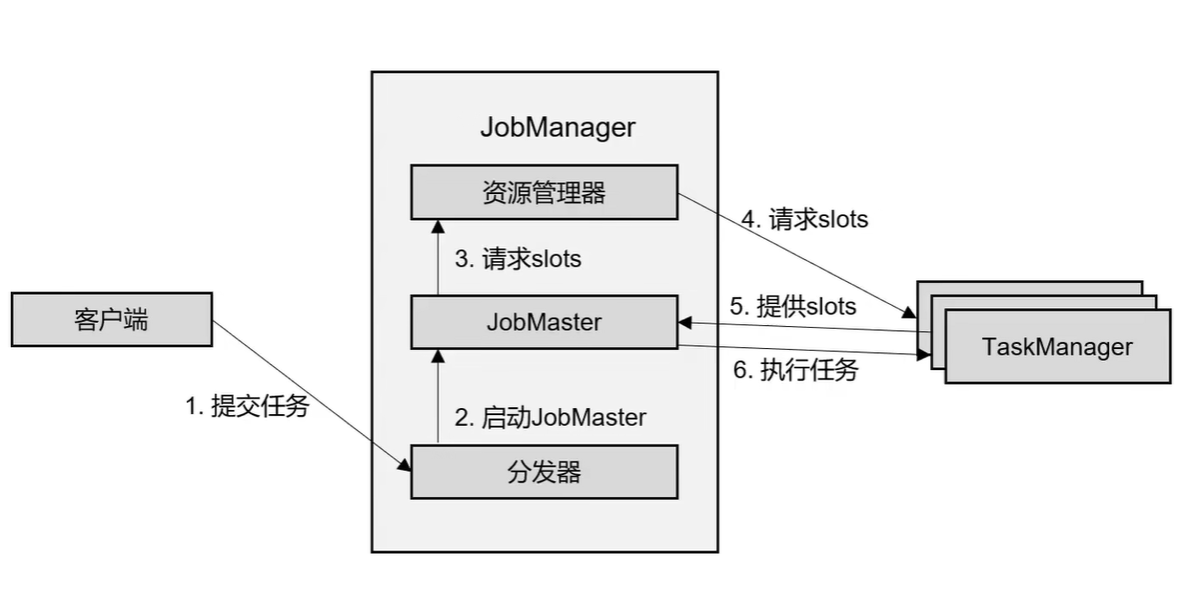
3. 作业提交流程
-
standalone模式作业提交流程
-
yarn会话模式作业提交流程
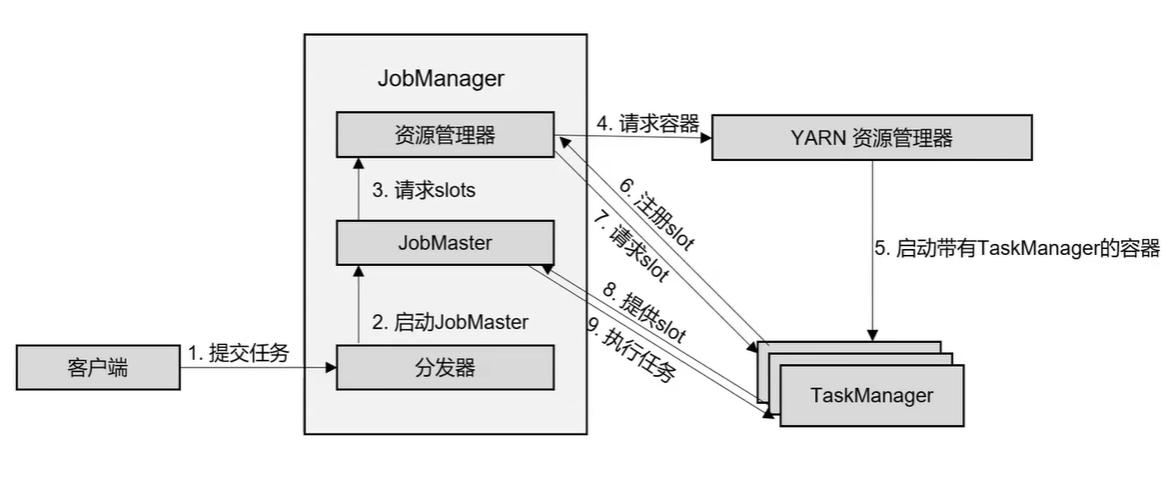
-
yarn单作业模式作业提交流程
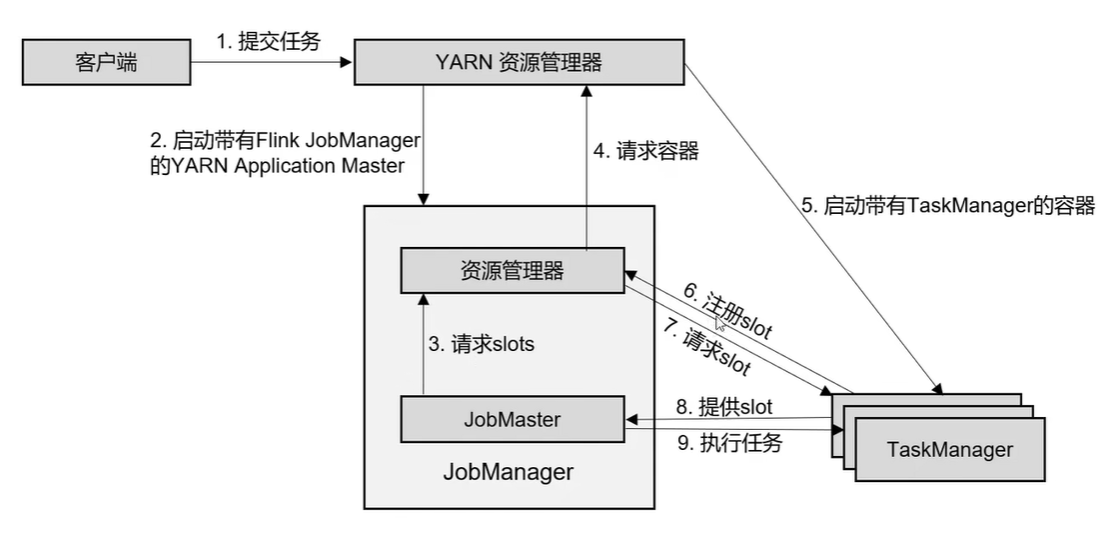
4. 重要概念
- 思考
- 怎样从Flink程序得到任务?
- 一个流处理程序,到底包含多少个任务?
- 最终执行任务,需要占用多少slot?
- 数据流图(dataflow)
- 在运行时,Flink上运行的程序会被映射成“逻辑数据流”(dataflows),它包含了source、transformation、sink这三部分
- 每一个dataflow以一个或多个sources开始以一个或多个sinks结束。dataflow类似于任意的有向无环图(DAG)
- 在大部分情况下,程序中的转换运算(transformations)跟dataflow中的算子(operator)是——对应的关系
- 并行度(parallelism)
- 每一个算子(operator)可以包含一个或多个子任务(operator subtask),这些子任务在不同的线程、不同的物理机或不同的容器中完全独立地执行。
- 一个特定算子同时处理多个子任务(subtask),叫做数据并行(通过拷贝一个算子镜像)。子任务的个数被称之为其并行度(parallelism)。
- 区别:多个算子分别处理多个子任务叫任务并行。
- coding
setParallelism(int parallelism)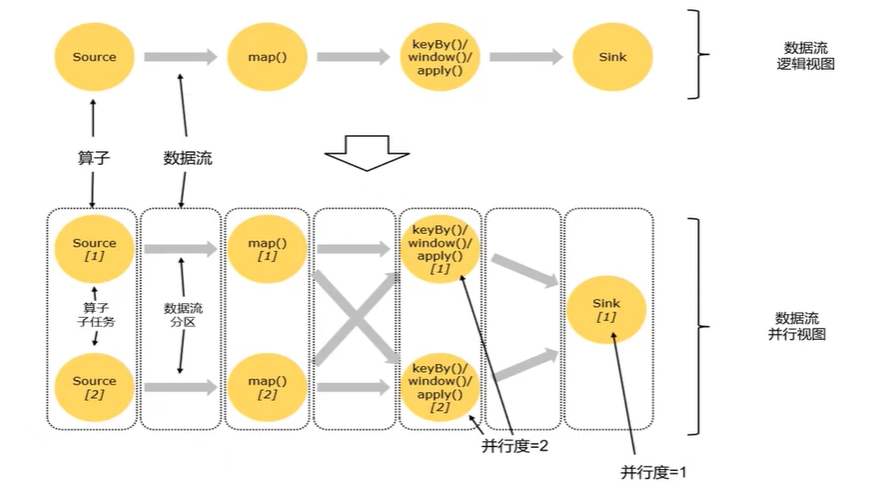
- 算子链(Operator Chain)
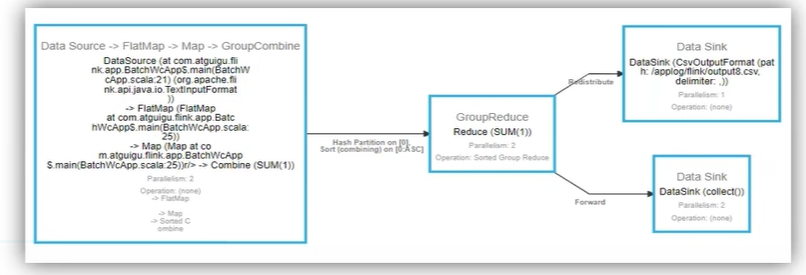
- 算子间数据传输关系:one-to-one,一对一关系。redistributing,重分区。
- 如上图,source->map 是 one-to-one 关系,map->keyBy 是 redistributing 关系。
- 一种称为任务链的优化技术:将两个或多个算子设为相同的并行度,并通过本地转发(local forward)的方式进行连接,达到减少本地通信的开销目的。
- 合并算子(task)的条件:必须是one-to-to操作,必须并行度相同。合并后形成新task,原来的算子称为里面的subtask。
- 如上图,source->map可以合并,map->keyBy不能合并(redistributing),keyBy->sum不能合并(并行度不统一)
- 执行图(ExecutionGraph)
- Flink 中的执行图可以分成四层: StreamGraph -> JobGraph -> ExecutionGraph -> 物理执行图
- StreamGraph:是根据用户通过Stream API编写的代码生成的最初的图。用来表示程序的拓扑结构。
- JobGraph: StreamGraph经过优化后生成了JobGraph,提交给JobManage的
- 数据结构。主要的优化为,将多个符合条件的节点chain在一起作为一个节点ExecutionGraph: JobManager 根据JobGraph生成ExecutionGraph。
- ExecutionGraph是JobGraph的并行化版本,是调度层最核心的数据结构。
- 物理执行图: JobManager根据ExecutionGraph 对Job进行调度后,在各个TaskManager上部署Task 后形成的“图”,并不是一个具体的数据结构。
- 任务槽(task slots)
- 任务和任务槽
- Flink中每一个TaskManager都是一个JVM进程,它可能会在独立的线程上执行一个或多个子任务
- 为了控制一个TaskManager 能接收多少个task,TaskManager通过task slot来进行控制(一个TaskManager至少有一个slot)
- 默认情况下,Flink 允许不同的算子(子任务)共享slot。这样的结果是,一个slot可以保存作业的整个管道。
- 当我们将资源密集型和非密集型的任务同时放到一个slot中,它们就可以自行分配对资源占用的比例,从而保证最重的活平均分配给所有的TaskManager。
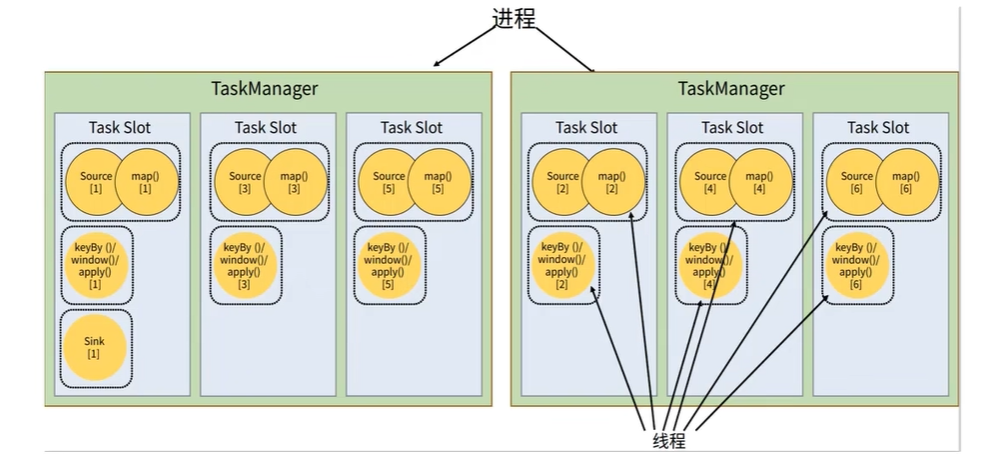 - 如上图,算子链的并行度有6,每个并行度分配一个槽位,并行中一整条作业管道的算子共享一个槽位。
- 如上图,算子链的并行度有6,每个并行度分配一个槽位,并行中一整条作业管道的算子共享一个槽位。
5. 任务调度
- coding
//禁用(合并)算子链。当前算子不能和前后任何算子合并算子链。
SingleOutputStreamOperator<T> disableChaining();
//开启新算子链。当前算子不能和后面的算子合并算子链(后面是新链)。
SingleOutputStreamOperator<T> startNewChain();
四、DataStream API
slotSharingGroup 算子共享组
1. 概述
- 一个Flink程序,其实就是对DataStream的各种转换。具体来说,代码基本上都由以下几部分构成,如下所示:
- 获取执行环境(execution environment)
- 读取数据源(source)
- 定义基于数据的转换操作(transformations)
- 定义计算结果的输出位置(sink)
- 触发程序执行(execute)
2. 执行环境(execution environment)
- 创建环境的方法 Environment.java
/*
1. 1.12版本前兼容
静态类:
StreamExecutionEnvironment 返回流处理环境,操作DataStream
ExecutionEnvironment 返回批处理环境,操作DataSet
工厂方法:
getExecutionEnvironment:智能地根据本地运行或jar包,返回本地环境或命令提交的集群环境。
createLocalEnvironment:返回本地环境
createRemoteEnvironment:返回集群环境,需指定参数jobManager的地址和端口、远程运行的jar包。
*/
StreamExecutionEnvironment.getExecutionEnvironment();
StreamExecutionEnvironment.createLocalEnvironment();
StreamExecutionEnvironment.createRemoteEnvironment("localhost",8888,"xxxx.jar","xxxx.jar");
ExecutionEnvironment.getExecutionEnvironment();
/*
2. 1.12版本后DataStream兼容流式和批式
代码设置:(硬编码,灵活性差)
RuntimeExecutionMode: STREAMING流式,BATCH批式,AUTOMATIC自动根据有无边界选择流式或批式。
命令行设置:
bin/flink runf -Dexecution.runtime-mode=BATCH ...
*/
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.STREAMING);
env.setRuntimeMode(RuntimeExecutionMode.BATCH);
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
- 既然存在有界流,为什么还要保留Mode.Batch?
- 流数据:Batch 不能处理流数据,所以流数据用Stream。
- 批数据:Stream的有界流处理数据时,没接受一个数据就会产生一次输出。但中间过程的数据对我们是多余的,直接输出最终结果会更高效,所以选择Batch。
3. 源算子(source)
- 约定接口 SourceFunction
- 方法:run - 开始读数据
- 方法:cancel - 终止读数据
- flink提供的方法举例,这里的env指代StreamExecutionEnvironment
- env.readTextFile 创建了 ContinuousFileMonitoringFunction
- env.socketTextStream 创建了 SocketTextStreamFunction
- Pojo类可以作为DataStream的泛型, Flink认定的POJO类型标准:
- 类是公有(public)的[文件:sushiPool.js]
- 有一个无参的构造方法
- 所有属性都是公有(public)的
- 所有属性的类型都是可以序列化的
- 引入source的方法(Source.java)
- 读socket文本流
- 读集合
- 读元素
- 读文件
- 读kafka
- 自定义数据源 - 直接实现SourceFunction接口的数据源并行度只能是1
- 自定义并行数据源 - 实现 ParallelSourceFunction 接口,允许设置并行度
4. transfer
5. sink
五、窗口
1. 概述
- Window:Window是处理无界流的关键,Windows将流拆分为一个个有限大小的buckets,可以可以在每一个buckets中进行计算
- start_time,end_time:当Window时时间窗口的时候,每个window都会有一个开始时间和结束时间(前开后闭),这个时间是系统时间
- event-time: 事件发生时间,是事件发生所在设备的当地时间,比如一个点击事件的时间发生时间,是用户点击操作所在的手机或电脑的时间
- Watermarks:可以把他理解为一个水位线,等于evevtTime - delay(比如规定为20分钟),一旦Watermarks大于了某个window的end_time,就会触发此window的计算,Watermarks就是用来触发window计算的。
2. 算子
- evitor:清理器,用于窗口执行计算函数前后移除窗口内元素(如计算后移除已计算的数据)。
3. QA
- 为什么设置了水位线,没有进入trigger的onEventTime事件,窗口函数没有触发? 答:i. 发送水位线:
- 新元素进入时,触发
org.apache.flink.streaming.runtime.streamstatus.StatusWatermarkValve#findAndOutputNewMinWatermarkAcrossAlignedChannels函数,检查channelStatuses的水位线最小值。如果大于lastOutputWatermark,那么就更新lastOutputWatermark的值,并emit一个新的水位线。channelStatuses是全部并行线程的集合。算子的并行度有多少,集合的大小就有多少。所以倘若CPU线程数是8,那么默认并行度就是8,只有输入8个元素后,channelStatuses才会填满,且发出的第一条水位线是第1个元素而不是第8个元素(假如输入的元素是升序的)。InputChannelStatus默认的水位线是Long.MIN_VALUE,所以如果输入的元素数量不到并行度,算子的水位线就是无穷小,不会触发trigger的onEventTime. ii. 触发timer- 新元素进入时,触发trigger的onElement事件,ctx.registerEventTimeTimer函数,会往
org.apache.flink.streaming.api.operators.InternalTimerServiceImpl#eventTimeTimersQueue里注册一个timer。- JobManager触发timer,
org.apache.flink.streaming.api.operators.InternalTimerServiceImpl#advanceWatermark这里的入参time就是上面emit的水位线,eventTimeTimersQueue就是上面注册的timer。当存在timer小于time,就会触发trigger的onEventTime函数。所以窗口事件没有触发的另一个原因可能是算子发出的水位线还没有到达窗口的结束时间(算子发出的水位线是并行度数量的线程中的最小值)。 iii. 窗口- trigger的onEventTime触发窗口process,但是此时窗口的elements和水位线是会继续接受WindowAssigner分发的元素。也就是说窗口内的元素和水位线是可以超过trigger触发的eventTime的。
- window的context拿不到trigger触发的时间戳。
九、状态
1、状态类型
- 托管状态(Managed State)和原始状态(Raw State)。
- 托管状态就是由 Flink 统一管理的,状态的存储访问、故障恢复和重组等一系列问题都由 Flink 实现,我们只要调接口就可以。托管状态是由 Flink 的运行时(Runtime)来托管的;在配置容错机制后,状态会自动持久化保存,并在发生故障时自动恢复。当应用发生横向扩展时,状态也会自动地重组分配到所有的子任务实例上。对于具体的状态内容,Flink 也提供了值状态(ValueState)、列表状态(ListState)、映射状态(MapState)、聚合状态(AggregateState)等多种结构,内部支持各种数据类型。聚合、窗口等算子中内置的状态,就都是托管状态;我们也可以在富函数 类(RichFunction)中通过上下文来自定义状态,这些也都是托管状态。
- 原始状态是自定义的,相当于就是开辟了一块内存,需要我们自己管理,实现状态的序列化和故障恢复。原始状态就全部需要自定义了。Flink 不会对状态进行任何自动操作,也不知道状态的具体数据类型,只会把它当作最原始的字节(Byte)数组来存储。我们需要花费大量的精力来处理状态的管理和维护。
- 算子状态(Operator State)和按键分区状态(Keyed State)
- common:每个并行子任务维护着对应的状态,算子的子任务之间状态不共享。
- 算子状态:算子的子任务实例共享状态
- 按键分区状态:算子的子任务中相同key的数据共享状态
2. 支持的结构类型
- 值状态(ValueState)
- 列表状态(ListState)
- 映射状态(MapState)
- 归约状态(ReducingState)
- 聚合状态(AggregatingState)
十、容错
十一、TABLE API & SQL
1. 创建表环境
//1. 定于环境配置
EnvironmentSettings settings = EnvironmentSettings.newInstance()
.inStreamingMode()
.useBlinkPlanner()
.build();
//2. 创建表环境
TableEnvironment tableEnv = TableEnvironment.create(settings);
2. 函数
- talbeEnv.createTemporaryView 创建虚拟表(视图),把table对象注册到tableEnv。
2. UDF 函数
关联文档
iceberg ddl
https://iceberg.apache.org/docs/latest/spark-ddl/
flink 官方文档(链接指向sql)
https://nightlies.apache.org/flink/flink-docs-release-1.15/zh/docs/dev/table/sql/queries/overview/
生产遭遇的问题
- state结合guava bloomFilter时,从检查点重跑报错:反序列化失败 原因:guava BloomFilter策略里的LockFreeBitArray是原子性的(加锁的),它的原子性实现的类在kryo反序列时失败 解决:使用flink包下shaded的BloomFilter,它使用非原子性的BitArray实现,是guava的简化版本。或者自己拷贝guava源码修复这个问题(这样做还可以顺便将guava哈希函数的64bit实现改成32bit实现,加快读写速度)。
- Charset.UTF-8 序列化失败(sun包下)
原因:sun包下的utf-8没有pulblic构造方法
解决:自己实现一个kryo的序列化器CharsetCustomNewSerializer(代码详见springDemo项目),并注册进flink环境
env.getConfig().registerTypeWithKryoSerializer(Charset.forName("UTF-8").getClass(), CharsetCustomNewSerializer.class)