
Window下安装启动
- window下载解压Redis-x64-version.zip
- cmd进入文件目录,执行
redis-server.exe redis.windows.conf启动服务端 - 再打开一个cmd进入文件目录,执行
redis-cli.exe -h 127.0.0.1 -p 6379启动客户端
Ubuntu/debian安装
- redis.io/docs ```bash curl -fsSL https://packages.redis.io/gpg | sudo gpg –dearmor -o /usr/share/keyrings/redis-archive-keyring.gpg
| echo “deb [signed-by=/usr/share/keyrings/redis-archive-keyring.gpg] https://packages.redis.io/deb $(lsb_release -cs) main” | sudo tee /etc/apt/sources.list.d/redis.list |
sudo apt-get update sudo apt-get install redis
### 一、Redis基础数据结构
#### 1. String
- 键值对:` SET key value [EX seconds] [PX milliseconds] [NX|XX]`、`GET key`
- 批量键值对:`MSET key1 value1 key2 value2 key3 value3`、`MGET key1 key2 key3`
- 扩展:`setNX`、`setEX`、`expire` 都可以通过五个参数的`set`命令实现(redis2.8扩展参数)
- 计数:`incr key`计数加1、`incrby key value`计数加n;计数不能超过Long.MAX
set codehole 9223372036854775807 – Long.Max OK incr codehole (error) ERR increment or decrement would overflow ```
2. List
- 相当于java的LinkedList,是链表不是数组,底层结构:linkList、zipList、quickList
- 插入删除是O(1),查询是O(n)
- 删除最后一个元素,数据结构自动删除,内存回收
- 可作队列(先进先出),可作栈(先进后出),2.4版本后PUSH接受多个值
LPUSH key value1 [value2]、LPOP key、RPUSH key value1 [value2]、RPOP key - 2.6版本后,弹出列表元素命令允许阻塞列表直到timeout或者发现可弹元素
BLPOP key1 [key2 ] timeout,BLPOP key1 [key2 ] timeout - list命令:https://www.runoob.com/redis/redis-lists.html
3. HASH(字典)
- 相当于java的HashMap,内部实现结构也与HashMap相同,值只能是String,是无序字典。
- 当 hash 移除了最后一个元素之后,该数据结构自动被删除,内存被回收。
- 键值对:
HSET key field value、HGET key field、HDEL key field1 [field2]、HGETALL key - 批量键值对:
HMSET key field1 value1 [field2 value2 ]、HMGET key field1 [field2] - 与String相比,hash更适合储存结构性的数据,适合对部分字段进行修改或获取的场景(String会将对象序列化,只能整存整取)
- set命令:https://www.runoob.com/redis/redis-hashes.html
4. Set(无序去重集合)
- 相当于java的HashSet,内部键值对无序唯一,有去重功能。内部实现相当于一个所有value都是null的字典(key、filed、value)。
SADD key member1 [member2]、SREM key member1 [member2]、SPOP key、SMEMBERS key、SISMEMBER key member- 可以计算并集、交集、差异、随机数
- set命令:https://www.runoob.com/redis/redis-sets.html
5. ZSet(有序去重集合+有分值SCORE)
- 保证内部唯一性,有score可以用于排序,底层实现结构是跳表。
- 可按score正序或逆序列出,可按分数区间正序或逆序遍历、可获取指定对象的score
- 添加
ZADD key score1 member1 [score2 member2] - 计数
ZCOUNT key min max、ZCARD key - 查询
ZRANGE key start stop [WITHSCORES]、ZREVRANGE key start stop [WITHSCORES]、ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT]、ZRANK key member - 删除
ZREM key member [member ...]、ZREMRANGEBYLEX key min max、ZREMRANGEBYRANK key start stop、ZREMRANGEBYSCORE key min max - zSet命令:https://www.runoob.com/redis/redis-sorted-sets.html
补充
- 容器性数据结构(List、Hash、Set、ZSet)共有特性:create if not exists 并且 drop if no elements
二、应用
1.分布式锁
- 考虑setNX和expire的原子性(新set五个参数,spring-data-redis需要2+以上版本,我用过的版本是2.1.2)
- 可重入性(使用ThreadLocal变量计数,客户端代码复杂,不推荐拓展可重入锁)。
2.延时队列
- 缺点:没有ack保证,即可靠性不完全可靠。
- 队列空了怎么办?答:队列空了,客户端反复pop,陷入死循环,浪费客户端cpu,拉高redisQPS。可以通过BLPOP、BRPOP解决(客户端sleep也行,但是会造成延迟问题)。
- 空闲连接自动断开?答:BLPOP/BRPOP会让Redis长时间阻塞,于是客户端会认为是闲置连接并主动断开,BLPOP/BRPOP会抛出异常。所以要做好错误重试。
- 获取锁冲突?答:1.直接抛出异常,通知用户稍后处理(人工点击重试等于错开了时间)。2.sleep后重试(危险:会影响后续任务,如果死锁会导致后续消息全部堵死)。3.将请求扔到另一个队列延后处理(适合异步)。
- 如何实现?答:用redis的ZSet。消息作为value,到期时间(延迟到几点几分几秒)作为score。然后用一个或多个线程轮询ZSet获取到期任务(多线程消费防止单线程挂掉,但也要考虑并发问题)。
- 为什么不可靠?答:1.redis未持久化,redis宕机后消息消失(redis有不定期写入磁盘的半持久化和随时写入磁盘的全持久化,前者不能保障可靠性)。2.redis没有ack机制,客户端拿到消息后宕机,消息消失。
3.位图
- 位数组的扩展,用01记录多位boolean值。
- 使用命令 零存
SETBIT key offset value、零取GETBIT key offset、整存SET key value、整取GET key(offset把最高位记作0,value是8位字节) - 魔术指令 bitfield 详见书
4.HyperLogLog(估数)
pfadd书中实验,数据规模在10w的时候,误差在277个,即0.277%。在标准误差0.81%的前提下,能够统计2^{64}264个数据。- 这个数据结构可以用在数据量大、需要去重、不必十分精确的数据统计中,如网站的UV(解决精度不高的统计需求)。
pfmerge可以合并2个HyperLogLog并去重。- 缺点:pf内存占用大,在数据大的情况下占用空间是12k字节(13684 * 6bit / 8 = 12k);在数据小的情况下会优化成稀疏存储。所以比如有千万用户,对每个用户建一个pf不合适。
- 为什么一个HyperLogLog占12k空间?在 Redis 的 HyperLogLog 实现中用到的是 16384 个桶,也就是 2^14,每个桶的 maxbits 需要 6 个 bits 来存储,最大可以表示 maxbits=63,于是总共占用内存就是 2^14 * 6 / 8 = 12k 字节。
5.布隆过滤器
- 用途:(防止缓存穿透)并发量高的时候,先通过布隆过滤器过滤掉不存在的(过滤掉90%),再查数据库判断是否存在,减轻数据库压力。
- 原理:布隆过滤器是一个长二进制向量(数组),输入值进行多次hash函数运算,add操作把所有运算结果对应的位数标1。exist操作发现所有hash计算位置都是1,则表示命中(存在)。
- 误差:布隆过滤器记录所有数据的key,因为通过随机散列映射,可能会有2个key的散列映射计算结果相同,于是被误判存在。多个key的散列计算结果集合包含了这个key的散列结算结果,也会导致误判。
- 命令:需要redis4.0版本,添加
BF.ADD、存在BF.EXISTS(1表示存在,0表示不存在)、批量添加BF.MADD、批量存在BF.MEXISTS - 参数:自定义创建命令
bf.reserve key error_rate initial_size错误率越低,需要的空间越大(default 0.01)。initial_size 参数表示预计放入的元素数量(default 100),当实际数量超出这个数值时,误判率会上升。JAVA的Redisson有封装。 - 内存实现:Guava提供了内存实现的布隆过滤器。
6.限流:滑动窗口算法(原书中的简单限流)
- 原理:用zset维护一个滑动时间窗口。key标记用户+行为,value是不重复随机数 如时间戳,score是行为发生时间。用户发生行为时,清除zset中过期数据,统计zset中剩余行为数是否超过限额,最后重新设定zset的key过期时间。
- 缺点:要记录所有用户行为,不能满足“限定60s内操作不能超过100万次”之类数据量大的需求。
7.限流:令牌桶算法(原书中的漏斗限流)
- 原书说是漏桶限流算法,但redis-cell不能做到匀速流出,只是能匀速生产令牌。
漏桶算法与令牌桶算法的区别:
- 漏桶算法是调用方将请求(水滴)放入桶中,主机匀速向网络上发送数据包,控制平滑的网络流量。即使遇到突发流量,也会被客户端存储起来,匀速生产请求。
- 令牌桶算法是服务方匀速向网络上提供令牌,获得令牌立即能获得服务,能控制平均网络流量,但允许出现突发流量将令牌一抢而空造成峰值的状态。
- 强行限制速率,平滑网络突发流量。
- 需要redis4.0,安装redis-cell拓展模块。
- 命令
CL.THROTTLE <key> <max_burst> <count per period> <period> [<quantity>]响应: 127.0.0.1:6379> CL.THROTTLE user123 15 30 60 1) (integer) 0 //0:action is allowed,1:action is limited/blocked 2) (integer) 16 //total limit of key(max_burst + 1) 令牌容量 3) (integer) 15 //remaining limit of key 剩余令牌 4) (integer) -1 //number of seconds until the user should retry, and always -1 if the action was allowed. 5) (integer) 2 //The number of seconds until the limit will reset to its maximum capacity. 多少秒后令牌会满。 - https://github.com/brandur/redis-cell
8.限流:漏桶算法
- 在redis-cell基础上与延迟队列配合。当成功流入桶中时,将请求加入延迟队列,利用延迟队列来实现匀速流出。
9.GeoHash
- 地理位置信息是经纬度的二维数组,GeoHash算法把地图分割成一个个小方块,将二维数组简化成一维数组。
- 详细原理:https://zhuanlan.zhihu.com/p/35940647
- API介绍:https://www.runoob.com/redis/redis-geo.html
10.Scan(查找符合正则的key)
- 原生keys命令缺点:1. 没有limit offset 2.复杂度O(n)且会阻塞进程
- redis2.8支持Scan命令:
SCAN cursor [MATCH pattern] [COUNT count]- 复杂度虽然也是 O(n),但是它是通过游标分步进行的,不会阻塞线程;
- 提供 limit 参数,可以控制每次返回结果的最大条数,limit 只是一个 hint,返回的结果可多可少;
- 同 keys 一样,它也提供模式匹配功能;
- 服务器不需要为游标保存状态,游标的唯一状态就是 scan 返回给客户端的游标整数;
- 返回的结果可能会有重复,需要客户端去重复,这点非常重要;
- 遍历的过程中如果有数据修改,改动后的数据能不能遍历到是不确定的;
- 单次返回的结果是空的并不意味着遍历结束,而要看返回的游标值是否为零;
- 扩展阅读:美团针对Redis Rehash机制的探索和实践
三、原理
1. 线程IO模型
- 基本模型: 非阻塞IO(NIO),多路复用(事件轮询)。
- 指令队列:redis给每个客户端socket关联一个指令队列。客户端的指令FIFO。
- 响应队列:redis给每个客户端socket关联一个响应队列。如果队列为空,说明连接空闲,将客户端描述符从write_fds移出,等队列有数据再放入。避免select系统调用返回写事件却发现没有数据,导致线程飙高cpu。
疑问:redis现在不是用epoll吗? - 定时任务:redis将定时任务维护在一个
最小堆中。每个循环周期,redis会处理堆顶的定时任务。处理完毕后,将下一个任务的等待时间作为select系统调用的timeout超时参数。于是,redis在timeout时间内可以放心睡眠。
疑问:redis现在不是用epoll吗?
2. 通讯协议
- RESP(Redis Serialization Protocol):Redis序列化协议。包含
- 单行字符串 以 + 符号开头。
- 多行字符串 以 $ 符号开头,后跟字符串长度。
- 整数值 以 : 符号开头,后跟整数的字符串形式。
- 错误消息 以 - 符号开头。 5、数组 以 * 号开头,后跟数组的长度。
- 数组 以 * 号开头,后跟数组的长度。
3. 持久化
- 快照法(rdb):一次全量备份。是内存数据的二进制序列化。
Redis 在持久化时会调用 glibc 的函数
fork产生一个子进程。子进程刚创建时共享父进程的代码段和数据段,返回大于0的pid给父进程,返回0给子进程,返回负数表示错误,如下:pid = os.fork() if pid > 0: handle_client_requests() # 父进程继续处理客户端请求 if pid == 0: handle_snapshot_write() # 子进程处理快照写磁盘 if pid < 0: # fork error当父进程需要写数据时,就会采用COW机制(CopyOnWrite),将需要修改的页面复制出来,其余页面不变。成千上万的页面只有少数页面需要分离出来,所以内存不会增长很多。子进程的数据页在子进程产生的瞬间就凝固了,所以叫快照。
-
AOF日志:连续增量备份。在长期运行过程中会变得无比庞大,如果数据库重启进行指令重放就会无比漫长。所以需要定期进行AOF重写。 AOF日志记录了Redis从创建开始所有写指令。通过重新执行顺序执行指令列表(重放)就能复现一模一样的redis数据库。 AOF日志会越来越大,可以用
bgrewriteaof指令对AOF日志进行瘦身。原理是开辟一个子进程,遍历内存转换成新的redis指令并存进新的AOF日志中。然后再将重写期间新的操作指令增量追加到新的AOF日志中。 Linux的glibc提供了fsync(int fd)函数可以将指定文件的内容强制从内核缓存刷到磁盘中。生产环境中通常配置成1s刷新一次。fsync是磁盘IO操作,频繁刷新会很慢。 - Redis4.0 混合持久化:快照+快照生成期间的操作指令AOF日志+后续AOF直到下次快照。能够快速恢复数据、缩小了AOF的大小;但4.0之前的版本不能识别该AOF文件,AOF文件中前半部分rdb可读性差。
4. 管道
- 管道就是客户端代码层面对读写请求顺序进行重排,将写请求排列在一起,将读请求排列在一起,节省网络耗时。
- 网络请求过程是这样的:客户端进程写数据到内核sendBuffer(write操作返回);客户端内核将写数据发送到网卡;客户端网卡将写数据发送到服务器网卡;服务器内核读取网卡写数据到recvBuffer;服务器进程从内核中取出写数据进行处理。 read操作与之相反,但需要客户端从内核中取出服务器发送的数据(最后一步)才返回。read操作只负责从本地内核缓冲区取数据,如果缓冲区是空的就会一直等待。所以wirte操作几乎没有耗时。第一个read操作有一个网络来回的耗时开销,后续read可以直接从缓冲区拿数据几乎瞬间返回。
5. 事务
- redis事务不满足严格意义上的原子性,只满足隔离性。当multi开启事务后,键入的redis命令会被放在队列中,而不会像sql那样在隔离环境执行。当执行exec后,所有队列命令会依次执行。如果有一句出错,会跳过它继续往下执行。当然也可以用discard取消命令队列,但前提你依然不知道命令中是否有异常。由此可见,redis的事务不满足传统关系数据库那样的回滚(不能全部成功/全部失败;只有取消,没有回滚)。
- redis提供watch命令,watch关键变量实现乐观锁。
6. 发布订阅(PubSub、消息多播)
- 之前提到redis作为消息队列的应用,但是这种方法不满足一个消息传递给多个客户端。老redis提供发布订阅功能,但有许多缺点,很少有使用场景。
- 缺点:生产者发布一个消息,如果没有订阅者,消息直接丢弃; => 订阅者1突然断连(挂掉),生产者发布消息,根据上行说明,redis只传递给其订阅者,订阅者1重连后也无法获得该消息,所以订阅者会永久丢失该消息。 => redis突然宕机,PubSub消息不会持久性,相当于丢失所有订阅者,所以消息会全部丢失。
- redis5.0新增Stream数据结构,带来了可持久化消息队列,或将取代PubSub。
7. 小对象压缩
- ziplist结构:当redis储存set、hash、zset结构,且足够小时,底层会用ziplist实现数据结构减少内存占用。数据规模需要满足下列条件:
i. hash-max-zipmap-entries 512 # hash 的元素个数超过 512 就必须用标准结构存储
ii. hash-max-zipmap-value 64 # hash 的任意元素的 key/value 的长度超过 64 就必须用标准结构存储
iii. list-max-ziplist-entries 512 # list 的元素个数超过 512 就必须用标准结构存储
iv. list-max-ziplist-value 64 # list 的任意元素的长度超过 64 就必须用标准结构存储
v. zset-max-ziplist-entries 128 # zset 的元素个数超过 128 就必须用标准结构存储
vi. zset-max-ziplist-value 64 # zset 的任意元素的长度超过 64 就必须用标准结构存储
vii. set-max-intset-entries 512 # set 的整数元素个数超过 512 就必须用标准结构存储 - 内存回收机制:删除1GBkey后,redis内存未必会减小1GB,因为redis内存回收以页为单位,只要一页上有一个key没有删除,这个页就不会被回收。但redis会重用尚未回收的页(空闲内存)。
- 内存分配算法:redis使用第三方库,比如facebook的jemalloc(默认)和google的tcmalloc。命令
info memory可用查看。
8. 主从同步
- CAP: redis满足可用性,放弃一致性,通过主从同步(从从同步)达到最终一致。
- 指令流同步(增量同步,基于内存buffer):主节点将写指令缓存在本地内存buffer中(定长环形数组),当buff数组满了,将从头覆盖。所以当(比如网络状态不好)不能及时同步,主节点的部分指令可能由于被覆盖而丢失,从节点将不能通过指令流完成同步,此时需要快照同步。
- 快照同步(基于磁盘文件):主节点将内存数据全部快照到磁盘文件中。将快照文件传送到从节点,文件IO很费资源。从节点清空全部数据,再全量加载快照文件。最后通过buffer更新快照同步期间的增量指令。如果此时buffer已经循环覆盖,又会触发快照同步,如果不能设置合适的buffer大小,就会无限循环。
- 快照同步(基于套接字,无盘复制):主节点通过socket将快照发送给从节点。主节点会一边遍历内存,一边将序列化内容发送出去;从节点保持不变,将接收的内容先储存在磁盘文件,再一次性加载。这样做减轻了主节点的性能损耗(文件IO对系统负载影响很大)。
- 增加从节点:需要先进行一次快照同步,再进行增量同步。
- wait指令:同步复制命令,会阻塞当前客户端,并将写命令同步到指定slaves。如果timeout参数为0,可能导致永久阻塞。
四、集群
1. 哨兵(Sentinel、中心化)
- 哨兵的作用:当master宕机时,自动化选出新的master,无需运维人工参与,能第一时间恢复线上故障。
- 哨兵原理:
- 对client:客户端连接哨兵集群(zookeeper),当客户端发现原master失联时,将从集群获取最新的master地址(新选出的),于是客户端能迅速与新master建立连接。
- 对redis:master、slaves均与哨兵集群连接,哨兵集群会监控所有主从节点的健康状态。当master宕机时,master会断开和客户端(clients)、主从复制(slaves)、哨兵集群(Sentinel)的连接,哨兵集群发现master异常后,会投票选出数据最完整的slave作为新的master。当旧master恢复后,重新接入哨兵集群,哨兵集群会通知它把它将为slave。因为redis主从数据不满足严格一致性(最终一致性),所以可能存在一定的消息丢失(2次同步间隙)。
- 消息丢失:由于主从最终一致,导致数据不能实时同步,有2个参数可以控制消息丢失程度。
min-slaves-to-write 1: 主节点至少有一个从节点在进行正常复制,否则对外停止写服务(丧失可用性)min-slaves-max-lag 10: 如果主节点10秒没收到从节点反馈,认为从节点不正常。
- 客户端如何知道主从切换地址变了?(原文基于py源码分析)
- 连接池建立新连接时,会查询主库地址,用查询主库地址与内存中主库地址比较,如果不同说明发生了主从切换。于是关闭所有连接,使用新地址重新建立连接。
- 主库被降级到从库后,客户端对旧主库发送修改性指令,会抛出
ReadOnlyError异常。客户端捕获到这个异常后,会知道主从切换了,会关闭所有旧连接,后续指令会重新建立新连接。
- 优缺点:
- 优点
(1) 哨兵模式是基于主从模式的,解决可主从模式中master故障不可以自动切换故障的问题。 - 不足-问题
(1) 是一种中心化的集群实现方案:始终只有一个Redis主机来接收和处理写请求,写操作受单机瓶颈影响。
(2) 集群里所有节点保存的都是全量数据,浪费内存空间,没有真正实现分布式存储。数据量过大时,主从同步严重影响master的性能。
(3) Redis主机宕机后,哨兵模式正在投票选举的情况之外,因为投票选举结束之前,谁也不知道主机和从机是谁,此时Redis也会开启保护机制,禁止写操作,直到选举出了新的Redis主机。
- 优点
2. Codis(中心化)
- Codis作用:单个Redis内存和CPU受限,利用Codis代理将多个redis实例聚集起来(集群),提高数据储存规模和高并发读写能力。
- Codis原理:客户端将请求发送到Codis中间件(Codis是无状态的,可以配置多个减小单节点压力),codis根据key将指令转发给后面的redis实例集群中对应的那个实例。codis不记录状态,仅起到转发的作用。
- key分片原理:为什么codis能把key转发到特定的redis实例?
- codis把所有key默认划分成1024个槽位(slot,数量可配置,默认1024个,算法是对key进行哈希,再模1024取余)。每个槽位都映射到一个redis实例(多对一关系)。
- 单codis会在内存中维护槽位与redis实例的关系;多codis需要在zk中维护这个关系(内存不能做到同步),并且提供Dashboard进行监控。
- 扩容原理、自动均衡(key的迁移):
- codis增加一个redis实例,就会重新调整槽位关系,把等比槽位的key转移到新redis。codis改造添加了命令SLOTSSCAN,用来遍历指定slot下的所有key。
- 当codis接收到新请求打到迁移中的key,怎么办?正常状态的key只会在一个redis实例中,迁移过程中key可能同时存在新旧reids实例中。codis不能直接判断出哪个是新的,于是它采取的办法是强制先对这个key进行迁移,迁移完成后再转发这个key的请求(此时这个key只在新实例上了)。
- 新增redis实例、系统空闲时,codis会观察每个redis实例对应的slots数量,如果不平衡,会自动迁移。
- 缺点-代价:
- 因为key分散在多个redis实例中,所以不支持事务了(此时的事务从数据库事务变成了分布式事务)。
- 因为key分散在多个redis实例中,所以许多操作不支持了(比如rename操作可能无法正确完成,因为当new_name在另一个redis实例上,可能错误判断new_name不存在)。
- 为了支持扩容,单个key的value不宜过大,单个集合结构总容量不宜超过1M,否则迁移可能会有卡顿。
- codis与单个redis相比增加了一个代理节点,所以网络开销比单个redis大,性能上也比单个redis略差。但性能损耗不明显,可以通过增加codis代理数量弥补(codis是无状态的,可以横向扩容)。
- codis集群通过zk实现配置中心,所以增加了zk运维成本(但是Dashboard能轻松监控redis实例,降低了对redis集群的人工运维成本)。
- codis不是官方亲儿子,redis有新特性,codis总要晚很多时间才能提供支持,无法实时保持跟进。
- 优点
- 设计上比redis-cluster简单,分布式问题由第三方(zk/etcd)处理,而cluster为了实现去中心化功能,写了复杂的代码,有大量配置参数调优,运维难度高。
3. Cluster(去中心化)
- Cluster原理:cluster将所有数据分成16384个slots,每个节点负责其中一部分槽位,并且存储槽位信息。客户端连接集群时,会得到一份槽位配置信息,所以客户端查询key时,可以直接定位到目标节点。cluster有纠错机制来校验调整客户端与服务器的槽位信息不一致。cluster的每个节点会将集群配置信息持久化写到配置文件中。
- 槽位定位算法:
- 默认对key进行crc32哈希,对哈希值进行16384取模,得到的余数就是槽位。
- 允许用户强制把key挂在某个槽位上。通过在key字符串里嵌入槽位的tag标记。
- 跳转MOVED(纠错)
- 当客户端向错误的节点发出指令,节点会向客户端返回一个特殊的跳转指令携带目标操作和目标地址,告诉客户端去连这个节点。
- 跳转指令
-MOVED 3999 127.0.0.1:6381,跳转到3999号槽位,地址是127.0.0.1:6381,’-‘表示是错误信息。 - 客户端接收到MOVED指令后,会纠正本地槽位表。
- 迁移
- 迁移的最小单位是槽位。迁移时,槽位在原节点状态为
migrating, 在新节点状态为importing. - 迁移工具
redis-trib首先会在源和目标节点设置好中间过渡状态,然后一次性获取源节点槽位的所有key列表(keysinslot指令,可以部分获取),再挨个key进行迁移。 - 过程:原节点dump序列化->目标节点restore反序列化->原节点删除key。整个过程是同步的,即原节点会阻塞直到key删除。所以key内容很大会导致卡顿。
- Client访问流程:
问题描述: 迁移过程中,key可能已经传输到目标节点,也可能任在原节点,如何处理?
(1) 客户端先访问旧节点,如果找到key,正常处理,否则返回-ASK targetNodeAddr重定向指令。
(2) 客户端向重定向地址发送不带参数的asking命令,要求打开REDIS_ASKING标识。
(3) 客户端在目标节点重新执行原来的操作命令。REDIS_ASKING标识是一个一次性标识。 一般情况下,客户端向节点发送槽位i的指令,如果槽位i属于这个节点,执行客户端操作命令。 如果没携带ASKING标识,并且槽位i不属于这个节点,会返回MOVED指令(即使正在导入槽位i)。 如果携带了ASKING标识,但节点没有导入槽位i,也会返回MOVED指令。 如果携带了ASKING标识,并且节点正在导入槽位i,会执行客户端操作命令。 所以如果步骤2不向目标节点先发送asking命令,目标节点会拒绝客户端的操作指令并返回MOVED命令重定向到原节点。
- 迁移的最小单位是槽位。迁移时,槽位在原节点状态为
- 容错
- 可设置主从节点,主节点故障,集群自动将某个从节点升级成主节点。
- (默认) 参数
cluster-require-full-coverage为yes时,一个槽位的主节点故障,但是没有从节点可以恢复,集群将不可用。 - 参数
cluster-require-full-coverage为no时,一个槽位的主节点故障,但是没有从节点可以恢复,集群(其他正常的槽位)仍可用,直到全部主节点故障且无从节点可恢复。
- 网络抖动
- 网络抖动会导致频繁主从切换,为了解决这个问题设置了以下参数配置。
- cluster-node-timeout:节点持续timeout的时间失联时,才可以认定该节点出现故障。
- cluster-slave-validity-factor:作为timeout的倍乘系数控制主从切换的松弛程度。
- 可能下线(PFAIL-Possibly Fail)与确定下线(Fail):Redis 集群节点采用Gossip协议来广播自己的状态以及自己对整个集群认知的改变。如果一个节点认为某节点失联(PFail),会向集群所有节点发送广播。如果一个节点收到某节点的可能失联(PFail)广播超过半数,就会认为这个节点是确定失联(Fail),然后向整个集群广播,并对该节点主从切换。
- 槽位迁移感知
- 问:cluster槽位正在迁移,或迁移完成,client如何感知?
答:cluster有2个特殊的error指令:moved、asking。 - moved:纠正槽位。客户端将指令发送到错误的槽位,服务端通知客户端刷新槽位关系表并重试指令。
- asking:临时纠正槽位。槽位处于迁移中时,旧节点查无数据,会返回一个asking让客户端去新节点尝试获取数据。这个动作中,客户端不会刷新槽位关系表。
- 重试2次:moved和asking是可能被连续使用的。例如,客户端先请求了错误槽位,然后moved去正确槽位。此时运维正在对这个槽位做迁移,于是客户端又会收到一个asking命令。
- 重试多次:moved和asking理论是是可能无限循环重试的。所以java、python客户端都设置了一个最大重试参数。
- 问:cluster槽位正在迁移,或迁移完成,client如何感知?
- 集群变更感知
- 目标节点挂了:客户端抛出个ConnectionError,然后会随机访问一个节点,于是就能拿到服务器返回的moved指令,更新槽位关系表。
- 手动修改集群信息,将某个master切换到新节点,将旧master移除:客户端访问旧master会得到ClusterDown的错误,被告知旧master所在集群不可用(因为移除后被孤立了),然后客户端会断开所有连接并清空槽位关系表。等下一条指令过来时会重新初始化节点信息。
五、拓展
1. Stream
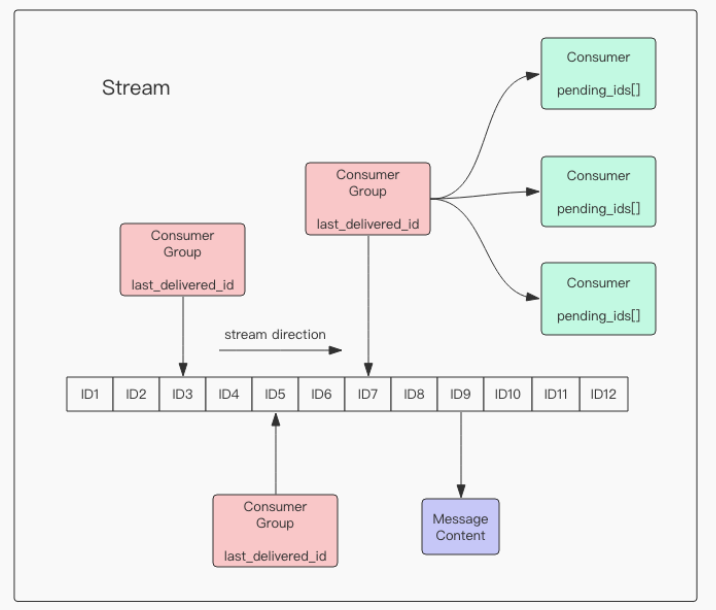
- redis5.0新特性。
- 支持多播的可持久化的消息队列,作者说借鉴了kafka。
- stream结构如上图所示,一个消息链表+多个消费组。每个消费组内有多个消费者。每个消费者维护自己未ack的id数组。
- stream: 每个stream都有唯一名称,即redis的key。
- 消息链表:
a. 消息ID格式为 timestampInMillis-sequence(毫秒时间戳-序号),例如1527846880572-5表示1527846880572毫秒的第5条消息。ID可以由服务器生成也可以由客户端指定。序号必须递增。
b. 消息内容为hash键值对。 - 消费组(Consumer Group):
a. 每个消费组都有独立的游标(last_delivered_id)。
b. 消费组名称在同一个stream内的是不重复的。消费组必须由指令创建,并指定游标,如xgroup create key groupname id-or-$($表示链表尾部,从新消息开始消费)。
c. 消费组状态独立,也就是说一份新消息可以被每一个消费组消费到。 d. 一个消费组内可以挂多个消费者,任意消费者消费了消息都会被认为是消费组已经消费了消息,游标会前进一格。 - 消费者(Consumer):
a. 消费者在同一个消费组内名称不能重复,互相为竞争关系,每条消息在组内只有一个消费者能消费到。
b. 消费者内部维护了一个数组变量
pending_ids,维护未ack的id,ack之后删除。官方称为Pending Entries List(PEL)。确保消息至少被消费一次,没有在网络中丢失。
- 消费:
- 独立消费
XREAD [COUNT count] [BLOCK milliseconds] STREAMS key [key ...] id [id ...]:
不定义消费组的情况下,把stream当普通的List用,需要客户端自己维护游标。 - Group消费
XREADGROUP GROUP group consumer [COUNT count] [BLOCK milliseconds] [NOACK] STREAMS key [key ...] ID [ID ...]
新consumer会自动创建。读到消息后,消息ID会存入消费者的PEL,客户端处理完毕后用XACK key group ID [ID ...]命令移出PEL。
- 独立消费
- 删除消息:
- Group只会记录游标,不会删除消息。对消息是增删要对stream本身操作。
XDEL key ID [ID ...]能删除指定stream的指定消息。XADD key MAXLEN ~ 1000 * ... entry fields here ...能设定stream最大长度,超出长度后会从头删除,如果有消息积压,可能会出现group未消费的消息由于消息溢出而被删除的情况。消息被删除不影响group的ack。
- ack:
- 确认ack是对group进行操作,redis能自己找到消息id属于group里的哪个consumer。
- 如果忘记ack,PEL列表会无限增长,内存消耗会无限增大。
- 可靠性&可用性:
- 客户端消费消息时,连接断开,消息丢失。客户端重连后,可以用
XPENDING命令从PEL读取已消费未确认的消息. - 兼容哨兵和集群模式下的主从复制。
- 客户端消费消息时,连接断开,消息丢失。客户端重连后,可以用
- 分区 Partition
- redis自己不提供分区。需要创建多个stream当作partition,再在客户端自己实现hash策略,自己实现分区。
2. info指令
- Server 服务器运行的环境参数
- Clients 客户端相关信息
- Memory 服务器运行内存统计数据
- Persistence 持久化信息
- Stats 通用统计数据
- Replication 主从复制相关信息
- CPU CPU 使用情况
- Cluster 集群信息
- KeySpace 键值对统计数量信息
3. 再谈分布式锁(redLock算法)
- 背景:在集群场景下,主节点挂掉,从节点取而代之。但是同步策略是异步同步,有一把锁没有同步到从节点。所以另一个客户端过来就可以申请到这把锁,不安全性由此产生。
- 算法原理:也采用『大多数机制』。redis需要提供多个无主从关系的实例。加锁时向所有节点发送set命令,半数成功才算成功。解锁时也向所有实例发送del命令。
- 争议:How to do distributed locking 『不伦不类』对于效率优先的锁来说有不必要的开销,对于安全优先的锁来说仍不能保证绝对的安全(主从不一致产生)。
4. 过期策略
- 主库策略
- 过期key集合:redis会把所有设置了过期时间的key放到一个集合中,通过定时扫描和惰性删除两种策略处理。
- 定时扫描:Redis默认每秒进行10次过期扫描,步骤如下:
(1) 从过期字典中随机 20 个 key;
(2) 删除这 20 个 key 中已经过期的 key;
(3) 如果过期的 key 比率超过 1/4,那就重复步骤 1;
每次扫描设置上限25ms,避免大量key同时过期,大量循环。但这仍然无法完全消除卡顿问题。比如某一秒大量key过期,并收到客户端101次请求。每次请求都要经历25ms扫描删除。第101个请求需要等待2500ms。 避免卡顿的解决方法是设置过期时间时,在目标过期时间上加一个随机数(比如最大一天的随机书),使得过期时间离散。 - 惰性删除:客户端访问一个key时,对key进行检查,如果过期,立即删除。
- 从库策略
- 从库不会主动进行过期扫描。从库等待主库发现key过期,在AOF文件内加上一句del指令。数据同步后,从库就会删除过期key。
- 由于主从不一致,会出现主库已经删除了,从库还未删除的情况,redLock算法的漏洞由这个同步延迟产生。
5. 内存淘汰算法:近似LRU
- 生产上不允许redis使用内存超出物理内存限制。否则内存会与磁盘频繁产生交换,对于访问频繁的redis来说,性能会急剧下降,这是不能忍受的。
- redis提供配置参数
maxmemory限制内存使用大小。 - redis提供以下几种页面淘汰算法:
| 算法 | 描述 |
|---|---|
| noeviction(default) | 不继续写请求(直到DEL数据腾出空间) |
| volatile-lru | 对设置过期时间的key集合进行最近最少使用算法 |
| volatile-ttl | 对设置过期时间的key集合进行最少生存时间算法 |
| volatile-random | 对设置过期时间的key集合进行随机删除算法 |
| allkeys-lru | 对所有key集合进行最近最少使用算法 |
| allkeys-random | 对所有key集合进行随机删除算法 |
- redis的近似LRU实现原理:redis给每个key增加24bit长度,记录最近访问时间戳。每次执行写操作,如果发现超出maxmemory,就随机抽样出5个key(数量可配置),淘汰最旧的,如果内存仍不够,继续这个操作。这个算法不用改变redis原本的数据结构(key),只会消耗少量内存(24bit per key)。
6. 懒惰删除(lazyFree,异步)
- Redis的网络分发、执行命令在主线程,但厚重的io比如关闭文件、刷盘还是会在后台有单独的bio线程。
- Redis4.0添加lazyFree线程,在后台异步处理删除工作。
- 背景:redis指令删除大对象,如有千万元素的key,del同步操作会造成卡顿。
- unlink指令:将key丢到后台异步回收内存。当执行unlink时,目标key已经逻辑删除,不会被主线程访问到,所以是线程安全的。如果unlink的对象是个小对象,会立即回收内存(与 del一致)。
- flush指令:flushdb、flushall也是极缓慢的操作,可以在后面加上async,即
flushdb async,扔给后台慢慢清理。 - 异步队列:主线程会将lazyFree的对象包装成一个任务,丢进异步任务队列。lazyFree线程读取这个队列。这个队列被主线程和lazyFree线程同时操作,所以必须是线程安全的数据结构。
- AOF Sync:redis每秒一次同步AOF日志到磁盘。它也是个很慢操作,自己有一个单独的线程,不影响主线程效率。
- 其他可配置异步删除点:
slave-lazy-flush:slave接收完RDB文件后清空数据选项
lazyfree-lazy-eviction:内存满逐出选项
lazyfree-lazy-expire:过期key删除选项
lazyfree-lazy-server-del:内部删除选项,比如rename srckey destkey时,如果destkey存在需要先删除destkey
以上4个选项默认为同步删除,可以通过config set [parameter] yes打开后台删除功能。 - 引用:《redis4.0之lazyfree》 https://developer.aliyun.com/article/205504
7. Jedis
- jedis客户端线程不安全,一般配合jedisPool连接池。使用完后要归还连接(close)。
- 代码控制重试。
8. 保护redis
- 指令安全:可以使用
rename-command指令把影响性能的指令重命名成更复杂的形式,如rename-command keys keysKeysKyes,避免手误打错。 - 端口安全:默认端口*:6379。为防止黑客攻击,应绑定监听ip,只允许白名单ip连接。还可以要求使用
auth指令进行身份认证(从库需要配置masterauth)。 - LUA脚本安全:应禁止用户输入内容(UGC)生产LUA脚本。应让redis以普通用户权限启动,这样即使被黑客攻击,也不会泄露root权限。
- SSL代理:redis不支持SSL连接,需要使用SSL代理,如SSH,官方推荐spiped。
9. redis安全通信(spiped)
- 内容为spiped的原理和使用介绍,略
六、源码(数据结构)
1. 『字符串』内部结构
struct SDS<T> {
T capacity; // 数组容量(最小int8 1byte)
T len; // 数组长度(最小int8 1byte)
byte flags; // 特殊标识位,不理睬它(1byte)
byte[] content; // 数组内容(capacity byte)
}
struct RedisObject {
int4 type; // 4bits
int4 encoding; // 4bits
int24 lru; // 24bits
int32 refcount; // 4bytes
void *ptr; // 8bytes,64-bit system
} robj; //总共16bytes
- 字符串的结构体是SDS,类似于java的ArrayList,capacity是content最大容量(可扩展),len是字符串实际长度。
- 泛型T的意义是可以根据字符串长度选择byte、short、int数据类型,最大程度节省内存。
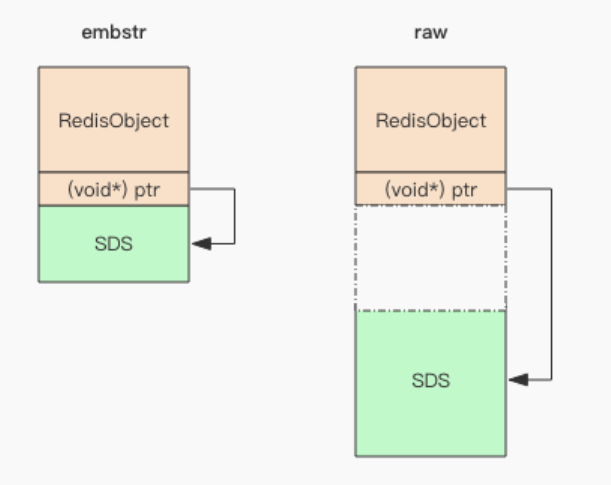
- 字符串在内存中的存储方式有两种(embstr/raw)。字符串在内存中分为redis对象头和SDS对象2个部分,redis对象头包含一个ptr指针指向实际SDS对象。embstr是redis对象头和SDS在内存中地址连续,使用malloc分配一次内存产生;raw是redis对象头和SDS在内存中地址不连续,需要使用malloc分配2次内存。
- 字符串长度≤44时使用embstr,大于44时使用raw,原因如下:内存分配的单位大小通常都是2的幂,这里选择64字节作embstr和raw的分界点。RedisObject头大小为16字节,SDS大小为字符串容量+3字节,字符串content中包含结束符'\0'1字节,所以总共可用长度为64-16-3-1=44字节。
2. 『字典』内部结构
- 数据结构: 类似java的hashMap,略过。 redisDB全局存了所有key的键值和过期时间:一个是<key,value>,另一个是<key,expireTime>。
- 扩容
- 缩容
3. 『压缩列表』内部结构
- 压缩列表是一块连续内存,没有冗余间隙。zset和hash在元素较小时会采用ziplist存储,节省内存。
- 数据结构:
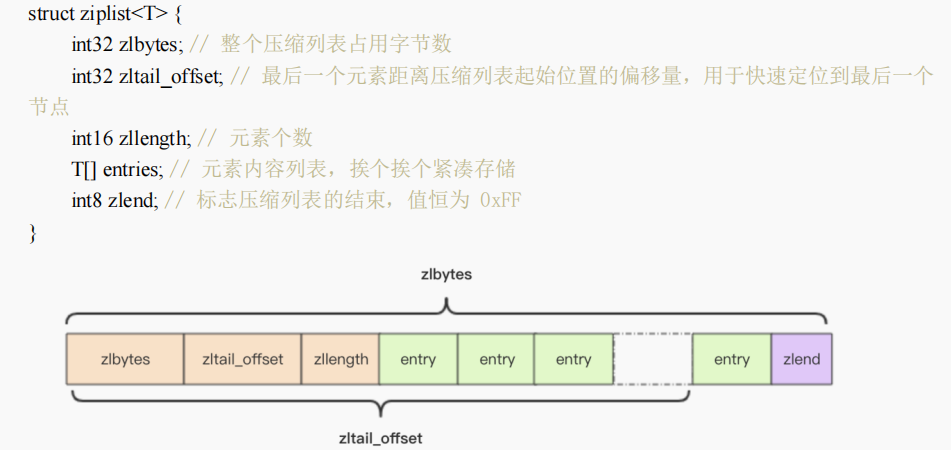
- entry结构:字符串长度小于254(0xFE)时,prevlen长度为1byte;字符串长度≥254(0xFE)时,prevlen长度为5byte,结构为0xFE(固定字节)+4个字节表示长度。

- 扩容:ziplist没有冗余空间,增加元素必须realloc重新分配内存再拷贝或在原基础上扩展。如果ziplist很大,重新分配内存性能消耗很大,所以ziplist只在小元素、少元素的情况下使用。
4. 『快速列表』内部结构
- 上文说到元素的列表适合用zipList,普通列表适合用linkedList(双向列表),两者混合就是quickList(快速列表)。
- 3.2之后list键使用quickList代替zipList和linkedList。
- quickList主要为了解决zipList重新分配内存问题。
- 数据结构:zipList可压缩成quicklistLZF。参数 list-compress-depth 默认是0。1表示首尾各1个不压缩,2表示首尾各2个不压缩,以此类推。
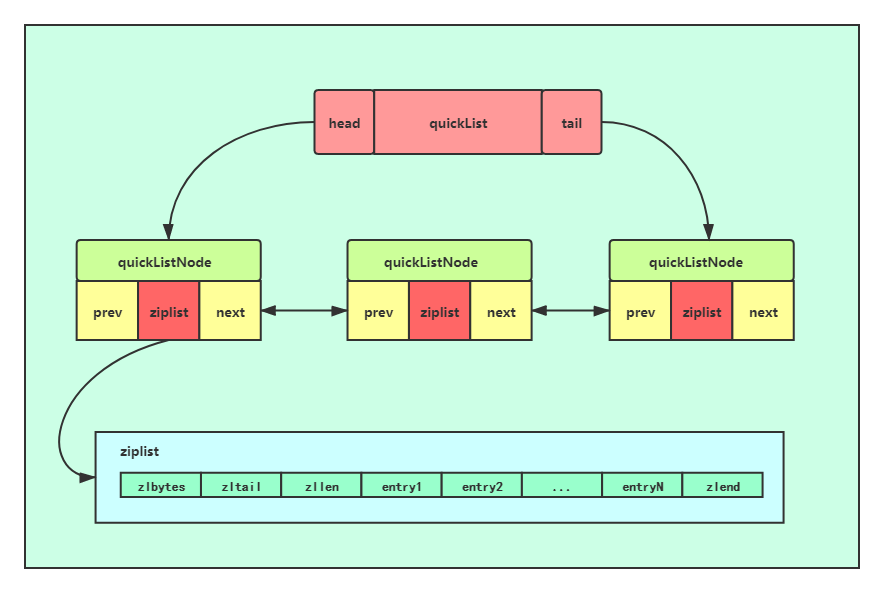
- 详细说明:《Redis数据结构——快速列表(quickList)》https://www.cnblogs.com/hunternet/p/12624691.html
5. 『跳表』内部结构
6. 『紧凑列表』内部结构
- redis5.0新增数据结构,目前只用在stream中(因为ziplist应用太广了,替换起来非常麻烦)。
- 目的:为了解决zipList级联更新(prevlen)和quickList额外空间开销(quicklistNode)问题。
- 数据结构:listpack可以通过total_bytes和最后一个lpentry最后一个字段length计算出最后一个entry的起始位置,所以省去了zltail_offset字段。
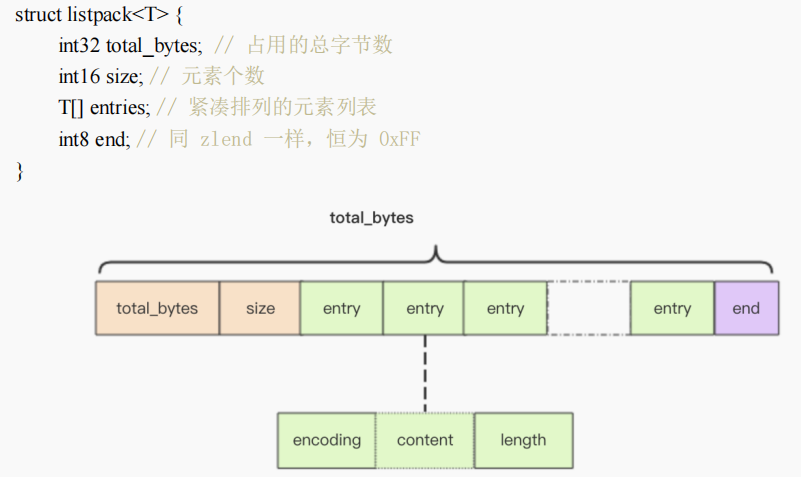
- entry结构:用当前节点长度length代替了前一节点长度prevlen,并且顺序调整到了最后。这样可以达到避免级联更新和省略zltail_offset字段2个目的。

7. 『基数树』内部结构
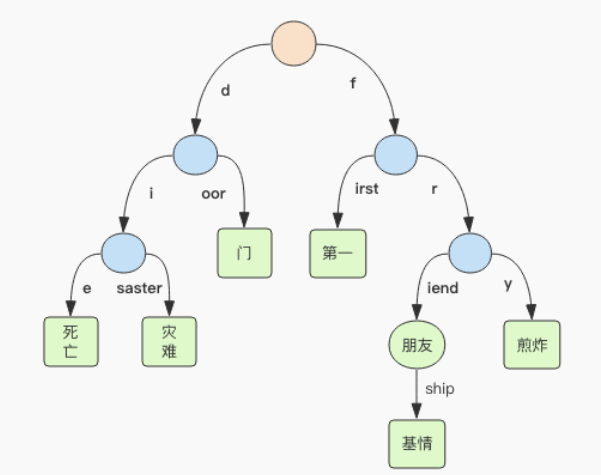
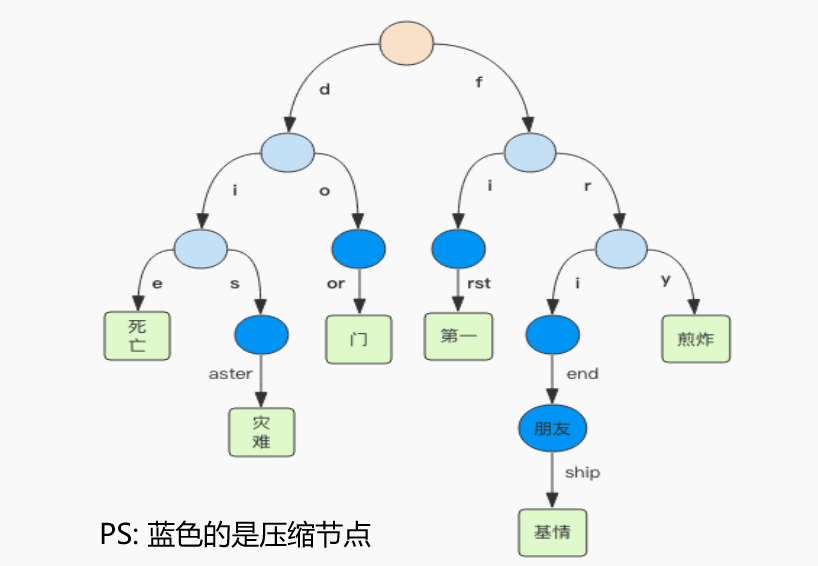
- RAX(radix tree)叫做基数树(前缀压缩树),就是有相同前缀的字符串,其前缀可以作为一个公共的父节点。
- Redis的stream的Id是时间戳+序号,使用rax结构可以快速定位消息。
- 子节点只有一个的节点叫压缩节点,如上右图。压缩节点的路由是一个字符串,非压缩节点的路由是一个字符。
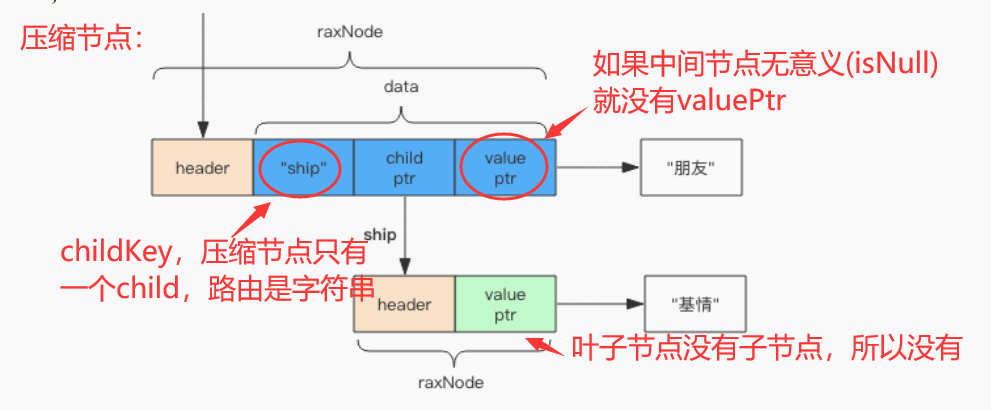
- 压缩节点结构:
struct raxNode {
int<1> isKey; // 是否没有 key,没有 key 的是根节点
int<1> isNull; // 是否没有对应的 value,无意义的中间节点
int<1> isCompressed; // 是否压缩存储,这个压缩的概念比较特别
int<29> size; // 子节点的数量或者是压缩字符串的长度 (isCompressed)
byte[] data; // 路由键、子节点指针、value 都在这里
} //节点结构
struct data {
optional struct { // 取决于 header 的 size 字段是否为零
byte[] childKey; // 路由键
raxNode* childNode; // 子节点指针
} child;
optional string value; // 取决于 header 的 isNull 字段
} //压缩节点data字段结构
- 非压缩节点结构:
struct data { byte[] childKeys; // 路由键字符列表 raxNode*[] childNodes; // 多个子节点指针 optional string value; // 取决于 header 的 isNull 字段 } //非压缩节点data字段结构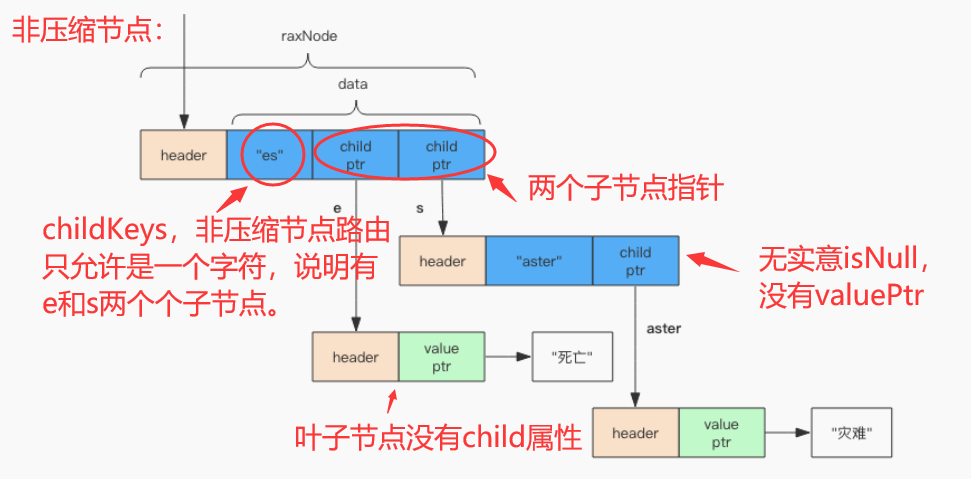
后记1. linux-源码安装redis(指定版本)
# 1. CentOS(yum)更新包管理器,安装gcc
sudo yum update -y
sudo yum install -y gcc tcl
# 2. Ubuntu(apt)更新包管理器,安装gcc
sudo apt update
sudo apt-get install build-essential tcl
# 3. 下载Redis 6.2.6
cd ~
mkdir redis
cd redis
wget http://download.redis.io/releases/redis-6.2.6.tar.gz
# 4. 解压缩
tar xzf redis-6.2.6.tar.gz
# 5. 编译Redis
cd redis-6.2.6
make
# 6. 安装Redis
sudo make install
# 7. 运行Redis
redis-server redis.conf
# 8. 检查端口判断是否启动
netstat -tunpl | grep 6379
后记、搭建redis集群
- 修改配置文redis.conf
#bind 127.0.0.1 #注释调,不限制ip daemonize yes #后台启动 protected-mode no #关闭保护模式 cluster-enabled yes #启用集群 cluster-config-file nodes_6379.conf #集群配置文件首次启动自动生成 cluster-node-timeout 15000 #超时时间 ## 单服务器多redis实例,拷贝一份redis.conf, 搜索所有6379, 把端口和文件名替换成新的端口号 stop-writes-on-bgsave-error no #rdb失败,不阻塞写入数据 - 启动单个服务:
- 分别在每台服务器上启动 Redis 服务:
- 集群需要至少3个主节点。假如设置备份1,至少需要6台redis-server实例。
- 单服务器上启动多个redis-server实例,要注意修改配置文件,端口和输出的文件名不能重复
redis-server /path/to/redis.conf
- 创建集群:
- 在第一台服务器上执行以下命令创建 Redis 集群:
## 省略,需要6个node redis-cli --cluster create <node1-ip:port> <node2-ip:port> <node3-ip:port> --cluster-replicas 1
- 在第一台服务器上执行以下命令创建 Redis 集群:
- 验证集群:
- 使用以下命令检查 Redis 集群状态:
```bash
redis-cli -c -h
-p cluster nodes redis-cli -c -h 172.31.56.10 -p 6379 cluster nodes
- 使用以下命令检查 Redis 集群状态:
```bash
redis-cli -c -h
5. 测试集群:
- 尝试在不同节点之间写入和读取数据,确保 Redis 集群正常工作。
- 以上是搭建 Redis 集群的基本步骤,如果需要更详细的指导或遇到问题,您可以参考 Redis 官方文档或咨询相关专业人士。请记住在操作前做好必要的备份和安全性考虑。
6. 运维命令:
```bash
## 检查集群状态
redis-cli --cluster check host:port
## 修复槽位有问题的节点
redis-cli --cluster fix host:port
## 修复槽位有问题的节点,遇到冲突需要人工处理时,强制覆盖
redis-cli --cluster fix host:port --cluster-replace
## 添加新的主节点
redis-cli --cluster add-node 新节点IP地址:端口号 现有节点IP地址:端口号 --cluster-master
## 添加新的从节点
redis-cli --cluster add-node 新节点IP地址:端口号 现有节点IP地址:端口号 --cluster-slave --cluster-master-id 主节点id
redis-cli –cluster reshard 172.31.56.10:6379
redis-cli –cluster create 172.31.39.163:6379 172.31.39.163:6380 172.31.32.71:6379 172.31.32.71:6380 172.31.81.251:6379 172.31.81.251:6380 –cluster-replicas 1
| netstat -tunpl | grep 63 |
rm nodes-6379.conf rm nodes-6380.conf
sudo redis-server redis.conf sudo redis-server redis_6380.conf